篇首语:本文由编程笔记#小编为大家整理,主要介绍了如何杜绝 spark history server ui 的未授权访问?相关的知识,希望对你有一定的参考价值。
默认状况下,Spark history Sever ui 是没有任何访问控制机制的,任何用户只要知道 shs 对应的 url,就可以访问链接查看 spark 作业的运行状况。
在证券基金银行等金融行业中,客户大都对信息安全有着较靠的要求,上述未授权访问的情况肯定是要杜绝的。那么如何配置以杜绝上述对 shs ui 的未授权访问呢?
在信息安全要求较高的环境中,我们推荐开启大数据集群的 kerberos 安全认证,从而对整个集群中的 hdfs/yarn/hive/hbase/kafka/zookeeper/spark 等服务提供认证保护。
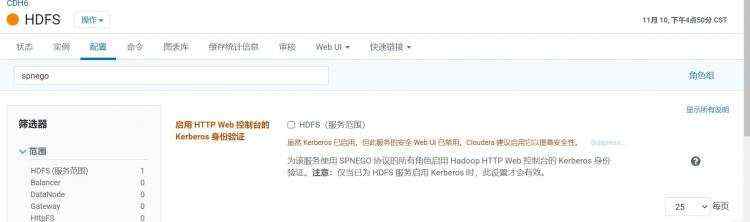



结合配置以下参数,即可控制对 SHS UI 的授权访问:
spark.history.ui.acls.enable=true
spark.history.ui.admin.acls=spark
spark.history.ui.admin.acls.groups
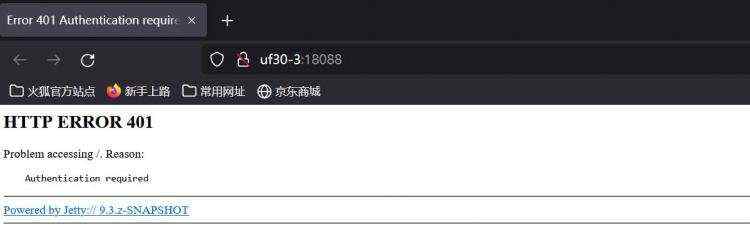
此时,通过浏览器访问 shs web ui 时,在没有经过 kerberos 安全认证时,就会报类似如下的错误:





spark.acls.enable
spark.admin.acls
spark.admin.acls.groups
spark.modify.acls
spark.modify.acls.groups
spark.ui.view.acls
spark.ui.view.acls.groups
spark.user.groups.mapping
spark.history.ui.acls.enable
spark.history.ui.admin.acls
spark.history.ui.admin.acls.groups



详细的配置参数如下:
//通过以下配置项开启了 shs ui 的 spnego 认证
spark.ui.filters=org.apache.spark.deploy.yarn.YarnProxyRedirectFilter,org.apache.hadoop.security.authentication.server.AuthenticationFilter
spark.org.apache.hadoop.security.authentication.server.AuthenticationFilter.param.type=kerberos
spark.org.apache.hadoop.security.authentication.server.AuthenticationFilter.param.kerberos.principal=HTTP/uf30-3@CDH.COM
spark.org.apache.hadoop.security.authentication.server.AuthenticationFilter.param.kerberos.keytab=spark_on_yarn.keytab
spark.org.apache.hadoop.security.authentication.server.AuthenticationFilter.param.kerberos.name.rules=DEFAULT\\u000A
//通过以下配置项,开启了 shs ui 的访问控制列表 acl,且配置了具体的 admin acl 为用户 spark 和用户组 spark
spark.history.ui.acls.enable=true
spark.history.ui.admin.acls=spark
spark.history.ui.admin.acls.groups=spark
//注意,以下配置项是 shs 在 rpc 通讯时的 kerberos 相关配置,这些配置影响的是 rpc 通信,跟是否开启 httpspnego 认证无关
spark.history.kerberos.enabled=true
spark.history.kerberos.principal=spark/uf30-3@CDH.COM
spark.history.kerberos.keytab=spark_on_yarn.keytab
//以下参数控制 Spark 内部各个进程进行 rpc 通信时是否需要经过认证,跟是否开启 http spnego 认证无关
spark.authenticate=true/false
4 未开启 kerberos 的大数据集群环境中,如何杜绝对 shs web ui 的未授权访问?
在没有开启 kerberos 的大数据集群环境中,对 shs ui 进行访问控制,仍需要使用上述 servlet 认证过滤器和访问控制列表机制;
由于 spark 本身并没有提供任何内置的认证 过滤器, 大家需要根据自己的认证机制自己实现一个认证过滤器,并配置参数 spark.ui.filters 使用该过滤器;
事实上,Hadoop 提供了一个 servlet 认证过滤器,即 org.apache.hadoop.security.authentication.server.AuthenticationFilter,和几个配套的认证机制的实现类,b包括 PseudoAuthenticationHandler/KerberosAuthenticationHandler/LdapAuthenticationHandler/MultiSchemeAuthenticationHandler/JWTRedirectAuthenticationHandler;
在没有开启 kerberos 的大数据集群环境中,大家可以重点看下 hadoop 提供的 LdapAuthenticationHandler/JWTRedirectAuthenticationHandler 认证过滤器,能否满足自己对 shs ui 认证的需要;

如果上述 hadoop 提供的认证过滤去不满足自己对 shs ui 认证的需要,大家需要根据自己的认证机制自己实现一个认证过滤器;
笔者在此提供一个简单的认证过滤器,该过滤器;
import org.apache.commons.codec.binary.Base64;
import org.apache.commons.lang3.StringUtils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import javax.servlet.*;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
import java.io.UnsupportedEncodingException;
import java.util.StringTokenizer;
/*
该类是一个简单的 servlet 安全过滤器,可以配置 spark history server web ui 使用该安全过滤器,以实现基本的访问控制
需要配合以下参数一起使用:
spark.ui.filters,spark.history.ui.acls.enable,
spark.history.ui.admin.acls,spark.history.ui.admin.acls.groups
*/
public class BasicAuthenticationFilter implements Filter
/** Logger */
private static final Logger LOG = LoggerFactory.getLogger(BasicAuthenticationFilter.class);
private String username = "";
private String password = "";
private String realm = "Protected";
/*
该方法使用指定的参数初始化该安全过滤器
具体参数包括:
用户名 username
密码 password
安全域 realm
*/
@Override
public void init(FilterConfig filterConfig) throws ServletException
username = filterConfig.getInitParameter("username");
password = filterConfig.getInitParameter("password");
realm = filterConfig.getInitParameter("realm");
if ( StringUtils.isBlank( username ) )
throw new ServletException( "No user provided in filter configuration" );
if ( StringUtils.isBlank( password ) )
throw new ServletException( "No password provided in filter configuration" );
if ( StringUtils.isBlank( realm ) )
throw new ServletException( "No realm provided in filter configuration" );
/*
该方法对 http 请求进行安全过滤,具体过滤逻辑是:
检查 http header 中 Authorization 是否为 Basic,并提取 header 中的用户名和密码
将 header 中提取的用户名和密码,跟初始化该过滤器时使用的用户名和密码进行对比,若一致则认证通过
其他情况则认证失败
*/
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain)
throws IOException, ServletException
HttpServletRequest request = (HttpServletRequest) servletRequest;
HttpServletResponse response = (HttpServletResponse) servletResponse;
String authHeader = request.getHeader("Authorization");
if (authHeader != null)
StringTokenizer st = new StringTokenizer(authHeader);
if (st.hasMoreTokens())
String basic = st.nextToken();
if (basic.equalsIgnoreCase("Basic"))
try
String credentials = new String(Base64.decodeBase64(st.nextToken()), "UTF-8");
LOG.debug("Credentials: " + credentials);
int p = credentials.indexOf(":");
if (p != -1)
String _username = credentials.substring(0, p).trim();
String _password = credentials.substring(p + 1).trim();
if (!username.equals(_username) || !password.equals(_password))
unauthorized(response, "Bad credentials");
filterChain.doFilter(servletRequest, servletResponse);
else
unauthorized(response, "Invalid authentication token");
catch (UnsupportedEncodingException e)
throw new Error("Couldn't retrieve authentication", e);
else
unauthorized(response);
@Override
public void destroy()
private void unauthorized(HttpServletResponse response, String message) throws IOException
response.setHeader("WWW-Authenticate", "Basic realm=\\"" + realm + "\\"");
response.sendError(401, message);
private void unauthorized(HttpServletResponse response) throws IOException
unauthorized(response, "Unauthorized");
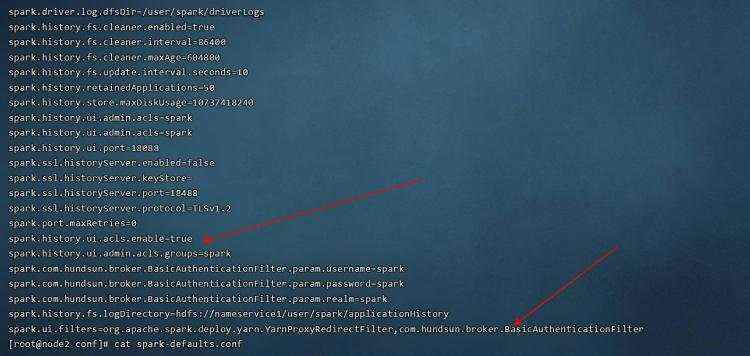
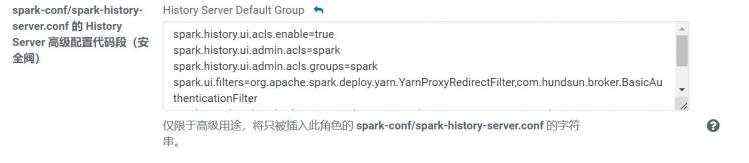
//通过以下配置项开启了 shs ui 的认证 - 使用自定义认证过滤器
spark.ui.filters=org.apache.spark.deploy.yarn.YarnProxyRedirectFilter,com.hundsun.broker.BasicAuthenticationFilter
spark.com.hundsun.broker.BasicAuthenticationFilter.param.username=spark
spark.com.hundsun.broker.BasicAuthenticationFilter.param.password=spark
spark.com.hundsun.broker.BasicAuthenticationFilter.param.realm=spark
//通过以下配置项,开启 shs ui 的访问控制列表 acl
spark.history.ui.acls.enable=true
spark.history.ui.admin.acls=spark
spark.history.ui.admin.acls.groups=spark











 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有